Using Generative AI to Complete Images
Introduction/Background
In modern times, we’re surrounded by technology that allow us to capture the world around us. Images often convey a large amount of information without using a single word. Thus, we wanted to create a project that manipulates images using software! For our project, we are focusing on image inpainting and intend to combine computer vision and artificial intelligence to achieve our goals. Image inpainting can be applied in cases where images have deteriorated or if there is a chunk missing from the image. Furthermore, we intend to take this further by implementing a way to replace the missing part of the image with a user requested image. As a result, images can either be restored to their original form or components of the image can be removed and replaced seamlessly.
Our motivation for pursuing image inpainting stems from our interest in using AI and computer vision to craft a useful tool for others. We hope to create programs that have the ability to restore images to a reasonable form. Furthermore, the ability to selectively remove parts of an image and replace it with a more suitable replacement is another motivation for us. We hope that this project will help us learn more about how technology can be leveraged to create art and how it can be used to improve existing images.
This topic is particularly interesting to research because it uses technology to create art and repair existing images. We look forward to researching how we can use algorithms to understand the context of each image and how we can fill in the missing areas in a way that is coherent for a human being. Image inpainting is a particularly interesting field due to its broad applications to art and computer science. Throughout the remaining weeks of this semester, we will focus on creating algorithms that can effectively fill in images and attempt to branch out and explore different methods of image inpainting.
Related Works:
Image inpainting, the technique to synthesize missing regions in an image, has been investigated by several research works. The major approaches relevant to our work include Generative Adversarial Network (GAN)-based models, diffusion-based models, and transformer-based models.
GAN-based models show promising performance in language-guided image inpainting. NUWA-LIP[1] leverages on VQGAN[6] which uses a GAN model to constrain the decoded images indistinguishable from the real ones. To effectively encode the defective input, the researchers introduce defect-free VQGAN which incorporates the relative estimation to decouple defective and non-defective regions, and to introduce relative estimation to control receptive spreading and symmetrical connections to retain the information of non-defective regions. In addition, the researchers propose a multi-perspective sequence-to-sequence module for enhancing visual information from complementary perspectives of pixel, token, and text domains. In addition to language-guided image inpainting, GAN-based models show satisfactory results in generating plausible image structures when dealing with large holes in complex images. For example, Cascaded modulation GAN (CM-GAN) [2], a network design consisting of an encoder with Fourier convolution blocks that extract multi-scale feature representations from the input image with holes and a dual-stream decoder with a cascaded global-spatial modulation block at each scale level, is capable of generating realistic results to fill removed areas that are large or causes distraction. In addition, the researchers propose object-aware training to add masks that contain accurate instance-level segmentation annotations in the training process as well as a masked-R1 regularization to stabilize the adversarial training.
Diffusion-based models can generate images based on conditional controls learned by neural networks for large pretrained text-to-image diffusion models like Stable Diffusion. ControlNet[3] is an end-to-end neural network architecture that learns diverse conditional controls. It preserves the quality and capabilities of the large model by locking its parameters and also making a trainable copy of its encoding layers, and then connecting these two components with zero-initialized convolution layers where weights are initialized to zeros so that they progressively grow during the training. This architecture ensures that harmful noise is not added to the deep features of the large diffusion model at the beginning of training, and protects the large-scale pretrained backbone in the trainable copy from being damaged by such noise. The researchers show that ControlNet can control Stable Diffusion with conditioning inputs including Canny edges, Hough lines, and segmentation maps, shedding lights on its application on image inpainting.
Transformer-based models take advantage of the attention mechanisms to address the long-range interactions in image inpainting. One such model, MAT, presented by Li et al. [4] has a customized inpainting-oriented transformer block where the multi-head contextual attention module aggregates non-local information only from valid tokens indicated by a dynamic mask in order to handle long-range dependencies. The researchers show that their design is capable of generating realistic contents for large masked-out areas that are not connected on high-resolution images.
In addition to these approaches, there are several approaches that are not based on GAN or diffusion frameworks. LaMa [7], a feed-forward ResNet-like network, has a single-layer architecture making it easy to train. In addition, to address the insufficient receptive field comprehension of Convolutional Neural Networks and ResNet-like networks, LaMa introduces Fast Fourier Convolution which takes advantage of the efficient Fast Fourier Transform algorithm to process a receptive field that spans the entire image. To train the model to generate more realistic image segments, LaMa introduces a multi-component loss that combines adversarial loss and a high receptive field perceptual loss and a training-time large masks generation procedure. Similarly, Jeevan et al. [5] propose a computationally-efficient fully convolutional architecture which uses a 2D-discrete wavelet transform for spatial and multi-resolution token-mixing along with convolutional layers. It does not require GAN or diffusion based training routines, and uses a simple single-stage network to restore the missing components in the images. These approaches deviate from the popular model backbones and results in visual outputs that are comparable to the results of models that are more complicated to train.
Methods/Approach:
Overview
The goal of our project was to create a generative model that could inpaint faces. In order to do this, we took a dataset of faces and tried to train different models and get a variety of results. This included WavePaint, GAN, and Diffusion models. We found that a pretrained Diffusion model was able to inpaint faces the best. The GAN was able to inpaint lower quality faces but struggled with high quality images. Even after significant tuning, we struggled to get the GAN to work consistently. Overall, we applied a variety of techniques and produced models that were able to accomplish the task we had set.
GAN Code:
Here’s our code for the GAN we were working on: https://drive.google.com/file/d/1aYO4C8s4hdEwHy9JzazEPwU3lu1VwAEi/view?usp=sharing
Here’s our code for the Control Net: https://colab.research.google.com/drive/18tWkqlDfMZyDyYgJbWl88QHS-zi1aGT8
Control Net Face Inpainting
This code initializes a diffuser network pipeline to inpaint images of celebrities after going through an image mask covering parts of their face. It uses the lllyasviel/control_v11p_sd15_inpaint pretrained network form Hugging Face.
One of the more successful image inpainting approaches we tried is using a diffusion network. Diffusion networks work well for generative AI purposes since they are trained to fill in data it believes fits in the missing or noisy input. We expected a diffusion network to work well for inpainting because we are inpainting facial features which are relatively consistent for humans. Other papers have explored inpainting the entire face to change the facial expression or art style. Our model is meant to inpaint parts of a face that have been masked rather than the entire face. Due to time and resource constraints, we used a pre-trained diffusion network structure from ControlNet. Originally, we planned on making a structure similar to Figure 1, and evaluating its performance, but the model significantly underperformed compared to the pretrained model. Instead, we tuned the pipeline parameters (prompt, masks, step number, etc.) until it generated a consistent output.
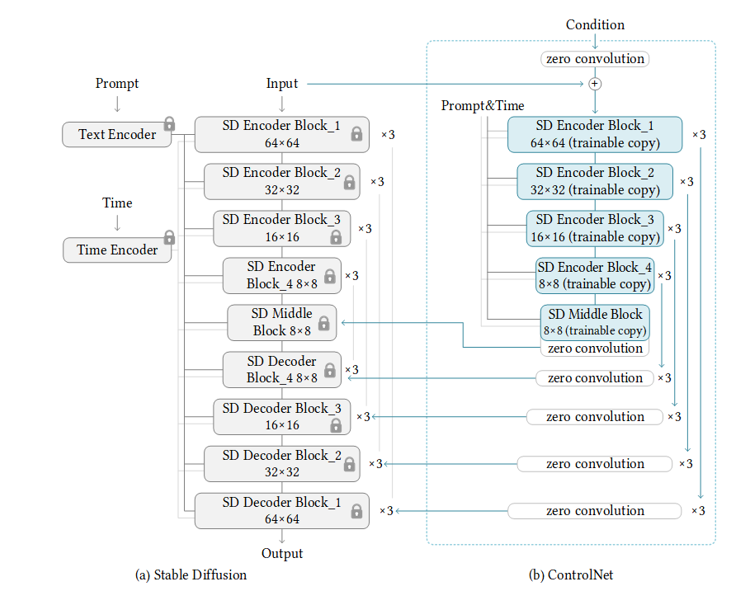
Figure 1: Pre-trained diffusion with ControlNet structure for inpainting from lllyasviel/control_v11p_sd15_inpaint/
Diffusion Model Experiment Setup:
To test the diffusion model, we used our validation set pictures and a set of masks as inputs. We randomly pair the pictures in the validation set with masks to generate masked images to generate the test set. After each picture ran through the pipeline, we assessed their accuracy using PSNR, SSIM, and MAE. Averaging the Additionally, we printed 20 of the set of input, masked, and output images side-by-side to assess them qualitatively.
Diffusion Model Results:

The outputs show that the generated images are very close to the ground truth. Specifically, the PSNR and SSIM show on average higher than 30 dB for the generated images and the SSIM is above 0.9 indicating good simDilarity between the original and generated images. We believe that this shows the diffusion network approach works for partial face inpainting.
Good Results:




Fair Results:




LaMa
After literature review, we find LaMa[7] a robust model to further investigate into to retrieve state-of-the-art results to which we can compare the result of our work. LaMa uses a feed-forward ResNet-like architecture, while replacing the residual blocks with Fast Fourier Convolution (FFC). An FFC block divides input image channels into two parallel pathways: (i) the local branch employs traditional convolutions with 3x3 kernel size, while (ii) the global branch utilizes real Fast Fourier Transform (FFT) to capture global context. Real FFT is suitable for real-valued signals, and the inverse real FFT guarantees real-valued output. Specifically, FFC contains the following steps: 1) applies Real FFT2d to an input tensor to map it to the frequency domain and concatenates real and imaginary parts; 2) applies a convolution block in the frequency domain; 3) applies inverse real FFT to recover a spatial structure. Finally, the local branch and the global branch are fused together. An illustration from the original publication is shown below:
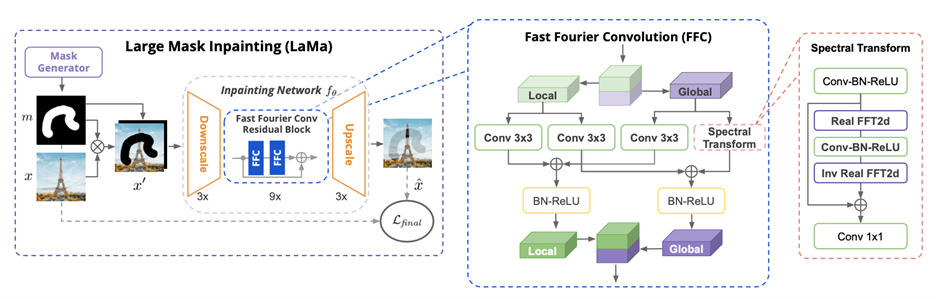
To generate robust output that oversees both naturally looking local details and consistency of the global structure, LaMa uses a weighed loss function, including adversarial loss used to govern local details, discriminator-based feature matching loss used to stabilize the training process, and perceptual loss used to guarantee consistent global structure recovery.
LaMa Experiment Setup
Due to time and computing resource constraints, we conduct experiments using pretrained model equipped with Fast Fourier Convolution (FFC) where there are 27M trainable parameters. We benchmarked the model performance using Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), and Mean Absolute Error (MAE) metrics. PSNR reflects ratio between the maximum possible power of a signal and the power of corrupting noise that affects the fidelity of its representation, and is suitable for measuring reconstruction quality for images. SSIM considers image degradation as perceived change in structural information. MAE reflects the mean of sum of absolute errors between paired observations. Testing images are drawn from CelebA-HQ dataset. Each testing image has a random mask uniquely generated as part of data preprocessing.
LaMa Experiment Results
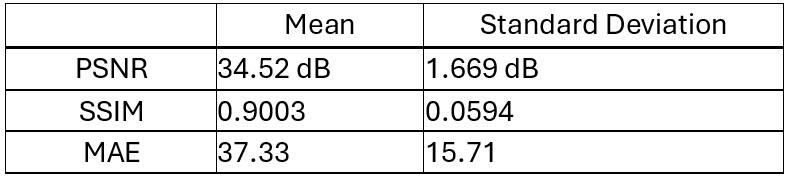
A PSNR result greater than 30 dB is considered good. An SSIM closer to 1.0 emphasizes less image degradation. An MAE result closer to 0 shows less discrepancy. Images used for testing are shown below. In each row, images are ordered as: 1) original test image, 2) masked test image, and 3) image after impainting by the model.
LaMa Image Results


Discussion and Takeaway
As a team, we learned so much along the away about which methods are more optimal for trying to complete images with missing sections. We applied what we learned from this course, along with information from our research to make decisions about how to approach this problem. Although not all of our attempts were successful, we’re proud of the results we ended up with, and we hope to use the skills we’ve learned from this project in our future projects and careers.
Challenges
The biggest challenge with this approach was trying to train the network from scratch. The T4 GPU from Colab would have taken days to train the model and the model’s accuracy did not seem to get better after a day of training. Resorting to the pre-trained model was the best way to get results for the diffusion approach, but future work would include training the model using a specific dataset to see if the results could improve.
Contributions:
Lucas - Introduction/Problem Definition, Github Page Formatting, GAN, Report Writing
Siam - Methods/Approach, Experiments/Results, GAN, Report Writing
Nikhil - Methods/Approach, Diffusion Model, Report Writing
Hanran - Related Works, LaMa, Report Writing
References
[1] M. Ni, X. Li, and W. Zuo, ‘NÜWA-LIP: Language Guided Image Inpainting with Defect-free VQGAN’, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023.
[2] H. Zheng et al., ‘CM-GAN: Image Inpainting with Cascaded Modulation GAN and Object-Aware Training’, arXiv preprint arXiv:2203. 11947, 2022.
[3] L. Zhang, A. Rao, and M. Agrawala, ‘Adding Conditional Control to Text-to-Image Diffusion Models’, IEEE International Conference on Computer Vision (ICCV). 2023.
[4] W. Li, Z. Lin, K. Zhou, L. Qi, Y. Wang, and J. Jia, ‘MAT: Mask-Aware Transformer for Large Hole Image Inpainting’, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
[5] P. Jeevan, D. S. Kumar, and A. Sethi, ‘WavePaint: Resource-efficient Token-mixer for Self-supervised Inpainting’, arXiv [cs.CV]. 2023.
[6] P. Esser, R. Rombach, and B. Ommer, ‘Taming Transformers for High-Resolution Image Synthesis’, arXiv [cs.CV]. 2020.
[7] R. Suvorov et al., ‘Resolution-robust Large Mask Inpainting with Fourier Convolutions’, arXiv [cs.CV]. 2021