Using Generative AI to Complete Images
Introduction/Problem Definition:
In modern times, we’re surrounded by technology that allow us to capture the world around us. Images often convey a large amount of information without using a single word. Thus, we wanted to create a project that manipulates images using software! For our project, we are focusing on image inpainting and intend to combine computer vision and artificial intelligence to achieve our goals. Image inpainting can be applied in cases where images have deteriorated or if there is a chunk missing from the image. Furthermore, we intend to take this further by implementing a way to replace the missing part of the image with a user requested image. As a result, images can either be restored to their original form or components of the image can be removed and replaced seamlessly.
Our motivation for pursuing image inpainting stems from our interest in using AI and computer vision to craft a useful tool for others. We hope to create programs that have the ability to restore images to a reasonable form. Furthermore, the ability to selectively remove parts of an image and replace it with a more suitable replacement is another motivation for us. We hope that this project will help us learn more about how technology can be leveraged to create art and how it can be used to improve existing images.
This topic is particularly interesting to research because it uses technology to create art and repair existing images. We look forward to researching how we can use algorithms to understand the context of each image and how we can fill in the missing areas in a way that is coherent for a human being. Image inpainting is a particularly interesting field due to its broad applications to art and computer science. Throughout the remaining weeks of this semester, we will focus on creating algorithms that can effectively fill in images and attempt to branch out and explore different methods of image inpainting.
Related Works:
Image inpainting, the technique to synthesize missing regions in an image, has been investigated by several research works. The major approaches relevant to our work include Generative Adversarial Network (GAN)-based models, diffusion-based models, and transformer-based models.
GAN-based models show promising performance in language-guided image inpainting. NUWA-LIP[1] leverages on VQGAN[6] which uses a GAN model to constrain the decoded images indistinguishable from the real ones. To effectively encode the defective input, the researchers introduce defect-free VQGAN which incorporates the relative estimation to decouple defective and non-defective regions, and to introduce relative estimation to control receptive spreading and symmetrical connections to retain the information of non-defective regions. In addition, the researchers propose a multi-perspective sequence-to-sequence module for enhancing visual information from complementary perspectives of pixel, token, and text domains. In addition to language-guided image inpainting, GAN-based models show satisfactory results in generating plausible image structures when dealing with large holes in complex images. For example, Cascaded modulation GAN (CM-GAN) [2], a network design consisting of an encoder with Fourier convolution blocks that extract multi-scale feature representations from the input image with holes and a dual-stream decoder with a cascaded global-spatial modulation block at each scale level, is capable of generating realistic results to fill removed areas that are large or causes distraction. In addition, the researchers propose object-aware training to add masks that contain accurate instance-level segmentation annotations in the training process as well as a masked-R1 regularization to stabilize the adversarial training.
Diffusion-based models can generate images based on conditional controls learned by neural networks for large pretrained text-to-image diffusion models like Stable Diffusion. ControlNet[3] is an end-to-end neural network architecture that learns diverse conditional controls. It preserves the quality and capabilities of the large model by locking its parameters and also making a trainable copy of its encoding layers, and then connecting these two components with zero-initialized convolution layers where weights are initialized to zeros so that they progressively grow during the training. This architecture ensures that harmful noise is not added to the deep features of the large diffusion model at the beginning of training, and protects the large-scale pretrained backbone in the trainable copy from being damaged by such noise. The researchers show that ControlNet can control Stable Diffusion with conditioning inputs including Canny edges, Hough lines, and segmentation maps, shedding lights on its application on image inpainting.
Transformer-based models take advantage of the attention mechanisms to address the long-range interactions in image inpainting. One such model, MAT, presented by Li et al. [4] has a customized inpainting-oriented transformer block where the multi-head contextual attention module aggregates non-local information only from valid tokens indicated by a dynamic mask in order to handle long-range dependencies. The researchers show that their design is capable of generating realistic contents for large masked-out areas that are not connected on high-resolution images.
In addition to these approaches, Jeevan et al. [5] propose a computationally-efficient fully convolutional architecture which uses a 2D-discrete wavelet transform for spatial and multi-resolution token-mixing along with convolutional layers. It does not require GAN or diffusion based training routines, and uses a simple single-stage network to restore the missing components in the images. This approach deviates from the popular model backbones and results in visual outputs that are comparable to the results of models that are more complicated to train.
Methods/Approach:
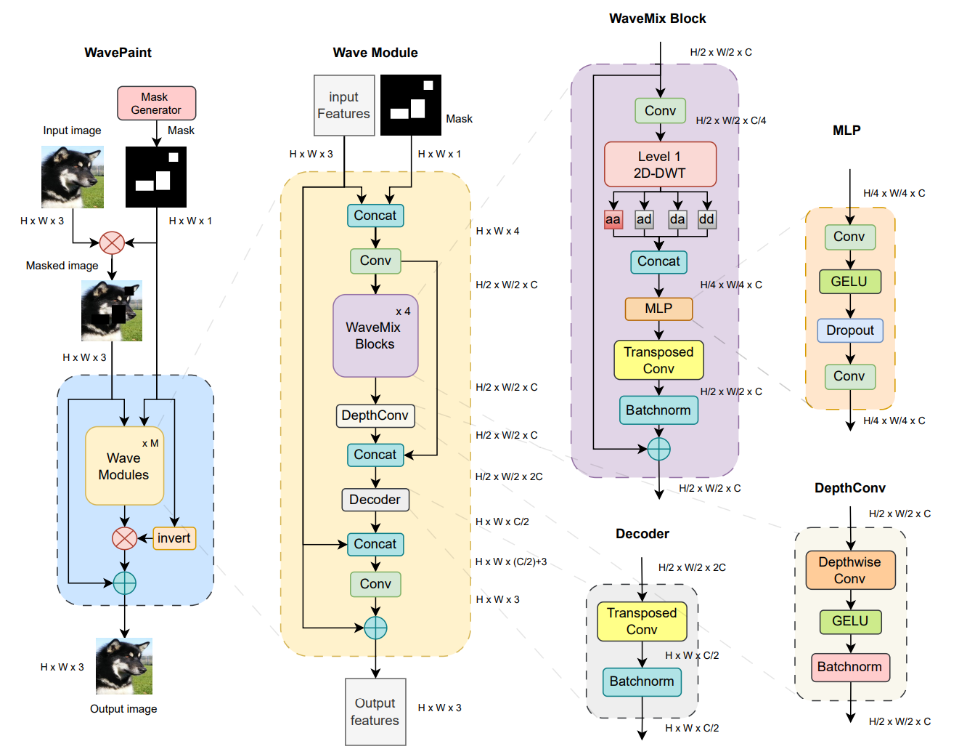
One approach we will try is the WavePaint Architecture. The architecture is within the scope of our
understanding, reasonable to implement, and is able to inpaint faces well. The architecture
generates a mask for an image and performs various operations we are familiar with like
convolution, dropout and GELU. Additionally, it uses a WaveMix module which consists of
convolutional layers, batch normalization, and a transposed convolution. Additionally, it performs a
new operation we will explore called Discrete Wavelet Transform which compresses the image
using high and low frequency filters. We will experiment with reducing the number of Wave
modules, as well as other aspects like the loss function and hyperparameters to train it for our
specific dataset. The architecture of the source is shown below :
Here is the loss function that we are using:
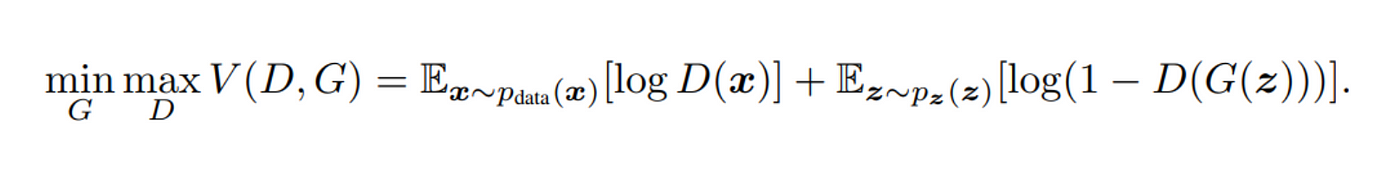
We would also like to evaluate the performance of a diffuser model called ControlNet. Diffuser models work by adding noise to the image and training the model to remove noise from the input image. ControlNet has a pre-trained diffuser model and allows for model conditioning with additional inputs such as canny edge, human pose, and depth. It has an inpainting model that takes the original image, a mask, and a prompt to infill the image.

We will explore how modifying the mask or input prompt changes the performance of the model. Hopefully this will reveal the ideal input conditions for face inpainting using this type of model.
We want to evaluate the models based on qualitative and quantitative methods. Qualitative evaluation will focus on how similar the faces look before and after the infill approach is applied. The evaluation will look for common patterns and problems that occur with each method. The quantitative evaluation methods we plan to use for these models include the following:
• Peak Signal-to-Noise Ratio (PSNR): Quantifies the noise/distortion present in an image by comparing the generated image to the original. A higher ratio indicates less noise meaning the generated image is closer to the ground truth.
• Structural SIMilarity (SSIM): Compares the structure of the generated image to the ground truth image by considering image properties such as luminance and contrast.
• Mean Absolute Error (MAE): Measures the average difference between the two images based on individual pixels. It computes a pixel-level accuracy of the image penalizing large differences in the generated parts of the image.
Experiments/Results:
Approach 1:
The first approach we attempted for image generation is a Generative Adversarial Network (GAN) and plan to apply it for inpainting. We implemented a simple GAN which consists of two neural networks going against each other. The Discriminator is a network that tries to distinguish between fake images from images in the dataset. The Generator is a network that tries to create an image from a noisy input that tries to look like a real image. The game involves the discriminator learning to distinguish between fake and real images well and the generator learning to fool the discriminator.
This is a diagram of the GAN Architecture:
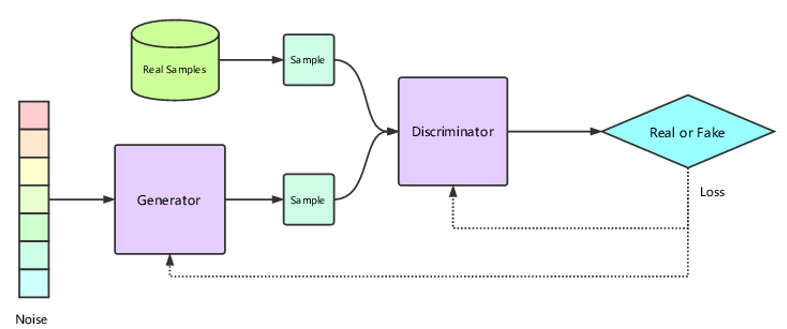
In our experiment, we used the CIFAR100 dataset as it is easy to load using TorchVision and consists of many images that are required to train a GAN. Our implementation is based on the Vanilla GAN, and we used this for reference. After 10 epochs, we had Discriminator Loss be 0.8886 and Generator Loss be 0.4564. The exported modules and a sample output are shown below. The next step we have is to modify the GAN for image inpainting. This can easily be achieved by instead of giving the generator noise, we use a masked image. We plan to base this implementation on an AOT-GAN.
Here’s the output of the trained Generator:

What’s Next:
Here is our task list. We will work as a team to complete each component by the date specified.
WavePaint Architecture - 4/2/24
Control Net Diffuser Model - 4/5/24
PSNR Code - 4/10/24
SSIM Code - 4/10/24
MAE Code - 4/10/24
Results Evaluation - 4/14/24
Visualizations - 4/14/24
Final Report - 4/18/24
Contributions:
Lucas - Introduction/Problem Definition, Github Page Setup/Formatting, Data Preprocessing, Report Writing
Siam - Methods/Approach, Experiments/Results, Report Writing
Nikhil - Methods/Approach, Report Writing
Hanran - Related Works, Report Writing
References:
[1] M. Ni, X. Li, and W. Zuo, ‘NÜWA-LIP: Language Guided Image Inpainting with Defect-free VQGAN’, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023.
[2] H. Zheng et al., ‘CM-GAN: Image Inpainting with Cascaded Modulation GAN and Object-Aware Training’, arXiv preprint arXiv:2203. 11947, 2022.
[3] L. Zhang, A. Rao, and M. Agrawala, ‘Adding Conditional Control to Text-to-Image Diffusion Models’, IEEE International Conference on Computer Vision (ICCV). 2023.
[4] W. Li, Z. Lin, K. Zhou, L. Qi, Y. Wang, and J. Jia, ‘MAT: Mask-Aware Transformer for Large Hole Image Inpainting’, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
[5] P. Jeevan, D. S. Kumar, and A. Sethi, ‘WavePaint: Resource-efficient Token-mixer for Self-supervised Inpainting’, arXiv [cs.CV]. 2023.
[6] P. Esser, R. Rombach, and B. Ommer, ‘Taming Transformers for High-Resolution Image Synthesis’, arXiv [cs.CV]. 2020.